
In the rapidly evolving world of cloud infrastructure, managing access and privileges efficiently is paramount. At AdAction, we embraced AWS Cloud Development Kit (CDK) to revolutionize Role-Based Access Control (RBAC) for their Amazon Redshift environments. Dive into our journey of transitioning from manual privilege management to an innovative, code-driven approach.
Evolution of Design Philosophy
Infrastructure as Code (IaC) is fantastic, and we’re enthusiasts. We provisioned our Redshift Clusters using the AWS Cloud Development Kit, and they’ve proven exceptionally easy to maintain. However, the administration of privileges for our databases and users continued to be a predominantly manual process involving the execution of SQL queries on the cluster. To address this, our team devised an innovative solution inspired by Redshift Alpha—the Amazon Redshift Construct Library. This solution empowers us to manage database privileges programmatically, enhancing efficiency and aligning with our code-driven approach.
Role-Based Access Control (RBAC) FTW!
In April 2022, Amazon Redshift introduced Role-Based Access Control (RBAC), which simplified the management of security privileges. Preceding the advent of roles, Redshift was dependent on groups for organizing privileges among users. The key distinction lies in the newfound capability of role-based organization to support nesting, enabling roles to inherit from other roles—a functionality previously unavailable with groups.
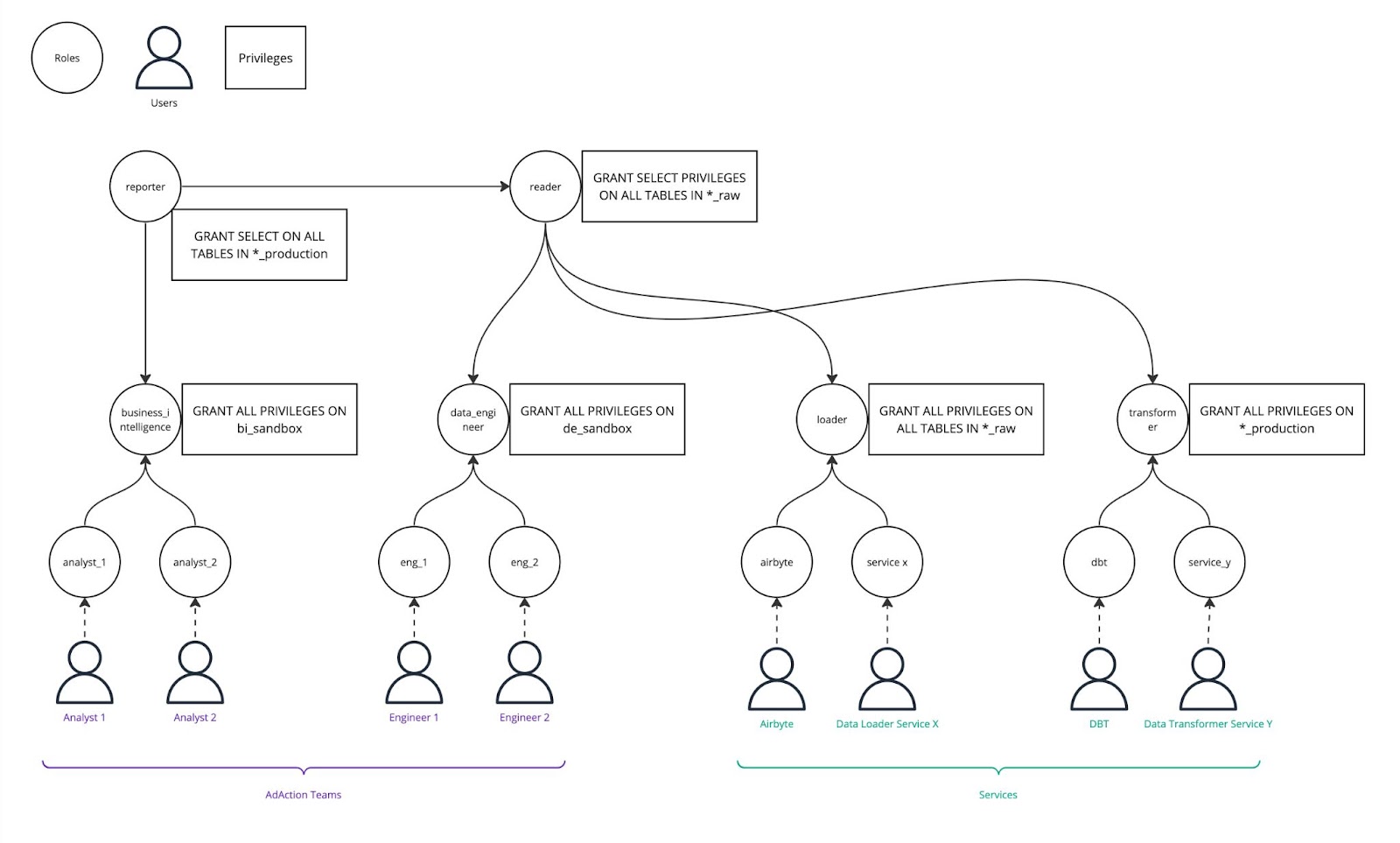
AdAction deals with large amounts of data that get accessed, analyzed, and processed by our analysts and product teams and consumed by products, and services, all while moving through a large network of interconnected data pipelines. Managing access to this data via groups was a huge pain because as we scale our operations there would be different groups that would get added and would need to be updated in all our data pipelines. The adoption of RBAC simplified this for us.
Infrastructure as Code as a Best Practice
At AdAction, we prioritize IaC for its pivotal role in accelerating our tech teams and fortifying the resilience of our cloud infrastructure. We also appreciate its capacity to reduce documentation needs, enabling developers to build on existing infrastructure code deployed by other teams in production. Given that the majority of our cloud infrastructure is provisioned on AWS, we’ve embraced the AWS CDK for the deployment of anything new slated for production.
In our recent initiative to modernize our data stack, the decision was clear – our new Redshift Clusters would be provisioned through code, yielding significant advantages. The data team can effortlessly make infrastructure changes with minimal risk, thanks to a meticulous process involving code reviews and testing integrated into our deployment pipeline.
CDK Constructs for RBAC
While deploying a new Redshift cluster with AWS CDK proved to be straightforward, and the introduction of RBAC streamlined our governance policies, managing the system posed certain complexities. Notably, there was a lack of CDK constructs designed to facilitate the control of access to our databases and schemas programmatically.
For instance, consider the scenario where we needed to grant write access to our BI analysts while restricting the rest of our organization to read-only access. In such cases, a data engineer would execute the queries (mentioned below) and subsequently update a master document that meticulously tracks privileges assigned to roles, teams, and users. Additionally, a query log is maintained to record every governance-related query executed.
GRANT ALL ON ALL TABLES IN SCHEMA schema_x TO ROLE business_intelligence; GRANT SELECT ON ALL TABLES IN SCHEMA schema_x TO ROLE reader;
This process raises obvious red flags.
- Engineers are manually executing queries on our production clusters without the benefits of testing, code reviews, and deployment automation as part of a CI/CD pipeline.
- The team is tasked with maintaining exhaustive and detailed documentation for a data store that encompasses data for our entire advertising network.
To address this issue, we developed custom TypeScript CDK constructs to programmatically provision databases, schemas, users, and grant the requisite roles and privileges to users. These constructs were integrated into the CDK App for our Redshift Data Warehouse which undergoes code reviews, encompasses test cases, and deploys seamlessly via a deployment pipeline. Since privileges are now managed as an app, we manage minimal documentation since privileges are defined with readable code.
Implementation of RBAC CDK Constructs
In implementing the RBAC CDK constructs, we drew inspiration from Redshift Alpha‘s higher level CDK constructs that are experimental and still under development. Utilizing AWS Custom Resource, we incorporated custom provisioning logic into our warehouse management CDK stack. AWS CloudFormation executes this logic whenever resources are created, updated, or deleted, (Custom Resource supports all CRUDL operations). These resources can be databases, tables, grants, users, and schemas that we need. For CRUDL operations, we leverage Lambda’s SingletonFunction and Redshift Data to execute queries on our Redshift Clusters.
For the context of this technical article, our focus will be exclusively on SQLResource for the provisioning of database privileges using RBAC. While we aim to open-source this module in the future, for now, we offer a detailed technical walkthrough of our implementation, accompanied by some helpful code snippets.
Defining a Base Construct for SQL Resources
In the code snippet below, we establish a custom CDK construct named SqlResource.This serves as a foundational element intended for utilization by subsequent higher-level constructs. SqlResource construct is formulated based on the strategy outlined earlier.
export class SqlResource extends Construct {
protected targetDb: string;
constructor(scope: Construct, id: string, props: SqlResourceProps) {
super(scope, id);
this.targetDb = props.targetDb;
const handler = new lambda.SingletonFunction(this, 'Handler', {
runtime: lambda.Runtime.NODEJS_18_X,
handler: 'index.handler',
timeout: cdk.Duration.minutes(1),
uuid: 'xxxx-xxxx-xxxx-xxxx-xxxx',
code: lambda.Code.fromAsset(path.join(__dirname, 'query-provider'), {
exclude: ['*.ts'],
}),
lambdaPurpose: 'Query Redshift Database Cluster',
role: props.executor.role,
});
const provider = new customresources.Provider(this, 'CustomResource', {
onEventHandler: handler,
});
new cdk.CustomResource(this, 'Resource', {
resourceType: 'Custom::RedshiftDatabaseQuery',
serviceToken: provider.serviceToken,
removalPolicy: props.removalPolicy,
properties: {
handler: props.type,
properties: props.properties,
clusterName: props.executor.clusterName,
secretArn: props.executor.secretArn,
targetDb: this.targetDb,
},
});
}
}
Using Redshift Data to Execute Queries
Next, we code for Lambda’s SingletonFunction, which is provisioned by the SQLConstruct resource. We define a function, executeStatement, that utilizes the Redshift Data Client to execute queries on a Redshift cluster. We invoke this function in Lambda’s Handler method to create databases, provide grants, etc.
import { GetStatementResultCommandOutput, RedshiftData } from '@aws-sdk/client-redshift-data';
import { SqlResourceQueryProps } from '../sql-resource';
const redshiftData = new RedshiftData({});
export async function executeStatement(
sql: string,
statementName: string,
sqlResourceProps: SqlResourceQueryProps,
): Promise<string> {
const executedStatement = await redshiftData.executeStatement({
ClusterIdentifier: sqlResourceProps.clusterName,
Database: sqlResourceProps.targetDb ?? 'default_db',
SecretArn: sqlResourceProps.secretArn,
Sql: sql,
StatementName: statementName,
});
if (!executedStatement.Id) {
throw new Error('Statement execution failed');
}
await waitForStatmentComplete(executedStatement.Id);
return executedStatement.Id;
}
async function waitForStatmentComplete(statementId: string): Promise<void> {
await new Promise((resolve: (value: void) => void) => {
setTimeout(() => resolve(), 100);
});
const statement = await redshiftData.describeStatement({ Id: statementId });
if (statement.Status === 'FINISHED') {
return;
} else if (statement.Status !== 'FAILED' && statement.Status !== 'ABORTED') {
return waitForStatmentComplete(statementId);
} else {
throw new Error(`${statement.Error}`);
}
Lamda Handlers
We code for the Handlers for Lambda Singletons as part of our SqlResource construct. For the scope of this article we only specify the handler for providing grants. The basic philosophy for executing queries via CDK remains the same across others.
export async function handler(props: SqlResourceQueryProps, event: CloudFormationCustomResourceEvent) {
if (event.RequestType === 'Create') {
await createGrant(props);
return {
PhysicalResourceId: getPhysicalResourceId(
`${props.properties.resourceName}-to-${props.properties.roleNames.join('-')}`,
props,
event.RequestId,
),
Data: {
resourceType: props.properties.resourceType,
resourceName: props.properties.resourceName,
roleNames: props.properties.roleNames,
},
};
} else if (event.RequestType === 'Delete') {
await revokeGrant(props);
return;
} else {
throw new Error(`Unsupported request type ${event.RequestType}`);
}
}
async function createGrant(props: SqlResourceQueryProps) {
if (kebab(props.properties.resourceType) === 'database') {
await grantRolesToDatabase(props.properties.resourceName, props.properties.roleNames, props);
} else if (kebab(props.properties.resourceType) === 'schema') {
await grantRolesToSchema(props.properties.resourceName, props.properties.roleNames, props);
} else if (kebab(props.properties.resourceType) === 'iam-db-user' || kebab(props.properties.resourceType) === 'service-db-user') {
await grantRolesToUser(props.properties.resourceName, props.properties.roleNames, props);
} else if (kebab(props.properties.resourceType) === 'role') {
await grantRolesToRole(props.properties.resourceName, props.properties.roleNames, props);
}
}
async function grantRolesToUser(name: string, roleNames: string[], sqlResourceProps: SqlResourceQueryProps) {
await executeStatement(
`GRANT ROLE ${roleNames.join(', ROLE ')} TO "${name}"`,
'grant-roles-to-user',
sqlResourceProps,
);
}
async function grantRolesToRole(name: string, roleNames: string[], sqlResourceProps: SqlResourceQueryProps) {
await executeStatement(
`GRANT ROLE ${roleNames.join(', ROLE ')} TO ROLE ${name}`,
'grant-roles-to-role',
sqlResourceProps,
);
}
...
Creating Higher Level SQL Resource Constructs for RBAC
With all the basic building blocks in place, we create higher-level constructs for Roles, Users, Schemas, and Databases. For the scope of this article, we showcase the code for the Role construct.
export class Role extends Construct {
readonly executor: SqlResourceExecutor;
readonly roleName: string;
readonly props: SqlResourceProps;
constructor(scope: Construct, id: string, props: RoleProps) {
super(scope, id);
this.executor = props.executor;
this.roleName = props.name;
this.props = props;
new SqlResource(this, `Role-${this.roleName}`, {
...this.props,
executor: this.executor,
type: 'Role',
properties: {
rolename: this.roleName,
},
handler: HandlerName.Role,
});
}
addToRoles(...roles: Role[]) {
const roleNames = roles.map((role) => role.roleName);
const grant = new SqlResource(this, `RoleGrant-${this.roleName}`, {
...this.props,
executor: this.executor,
type: 'Grant',
properties: {
resourceType: 'Role',
roleNames: roleNames,
resourceName: this.roleName,
},
handler: HandlerName.Grant,
});
roles.forEach((role) => {
grant.node.addDependency(role);
});
}
}
Consuming Constructs in a CDK Stack for Governance of Privileges
Having created the advanced constructs, we proceed to integrate them into our CDK Stack. At any given moment, whether it’s for modifications, deletions, or additions of new roles, we have the flexibility to perform these actions directly within this stack.
export class DataWarehouseInitializerStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: DataWarehouseInitializerStackProps) {
super(scope, id, props);
// For role hierarchy
const reporter = this.role("reporter");
const reader = this.role("reader");
reader.addToRoles(reporter);
const transformer = this.role("transformer");
transformer.addToRoles(reader);
const loader = this.role("loader");
loader.addToRoles(reader);
...
}
private role(name: string) {
return new Role(this, `Role-${name}`, {
executor: this.executor,
name,
targetDb: this.executor.defaultDb,
});
}
}
Insights and Innovations
In this exploration, we delved into Infrastructure as Code (IaC), leveraging AWS Cloud Development Kit (CDK) to streamline Redshift Cluster provisioning. The introduction of Role-Based Access Control (RBAC) in Amazon Redshift brought pivotal improvements, simplifying security management.
Facing challenges in access control using CDK, we developed custom constructs that were seamlessly integrated into the CDK App for the Redshift Data Warehouse. RBAC CDK constructs were implemented, drawing inspiration from Redshift Alpha, employing AWS Custom Resource for provisioning logic. A spotlight on SQLResource showcased its role in providing database privileges via RBAC, with plans for open-sourcing. Higher-level constructs for Roles, Users, Schemes, and Databases were created, emphasizing the flexibility within the CDK Stack for modifications.
In conclusion, our journey underscores a commitment to IaC best practices, the transformative impact of RBAC, and the development of tailored CDK constructs for effective privilege governance. As we share experiences, we aim to contribute to the broader tech community’s growth and innovation.
References:
- AWS Repost – “Amazon Redshift Roles (RBAC)” Link
- AWS CDK Documentation – “aws-cdk-lib.CustomResource” Link
- AWS CloudFormation Documentation – “Template Custom Resources” Link
- AWS CDK Documentation – “aws-cdk-lib.aws_lambda.SingletonFunction” Link
- AWS CDK Documentation – “aws-redshift-alpha-readme” Link
Contributing Author: Ron White
I am a Software Architect at AdAction. Currently, I’m primarily supporting the Data Team in its effort to build a modern data pipeline. I love problem-solving and consider myself a true polyglot. With over 25 years of experience wrangling software and almost 10 years wrangling children, I bring a diverse set of skills to our projects.

As Staff Software Engineer at AdAction, Nishanth spearheads the modernization of the data team, focusing on enhancing data systems and team skills. With a strong background in cloud and software architecture, he excels in navigating software teams through intricate challenges. Beyond work, he’s passionate about food, fitness, and exploring new techno and house music.